
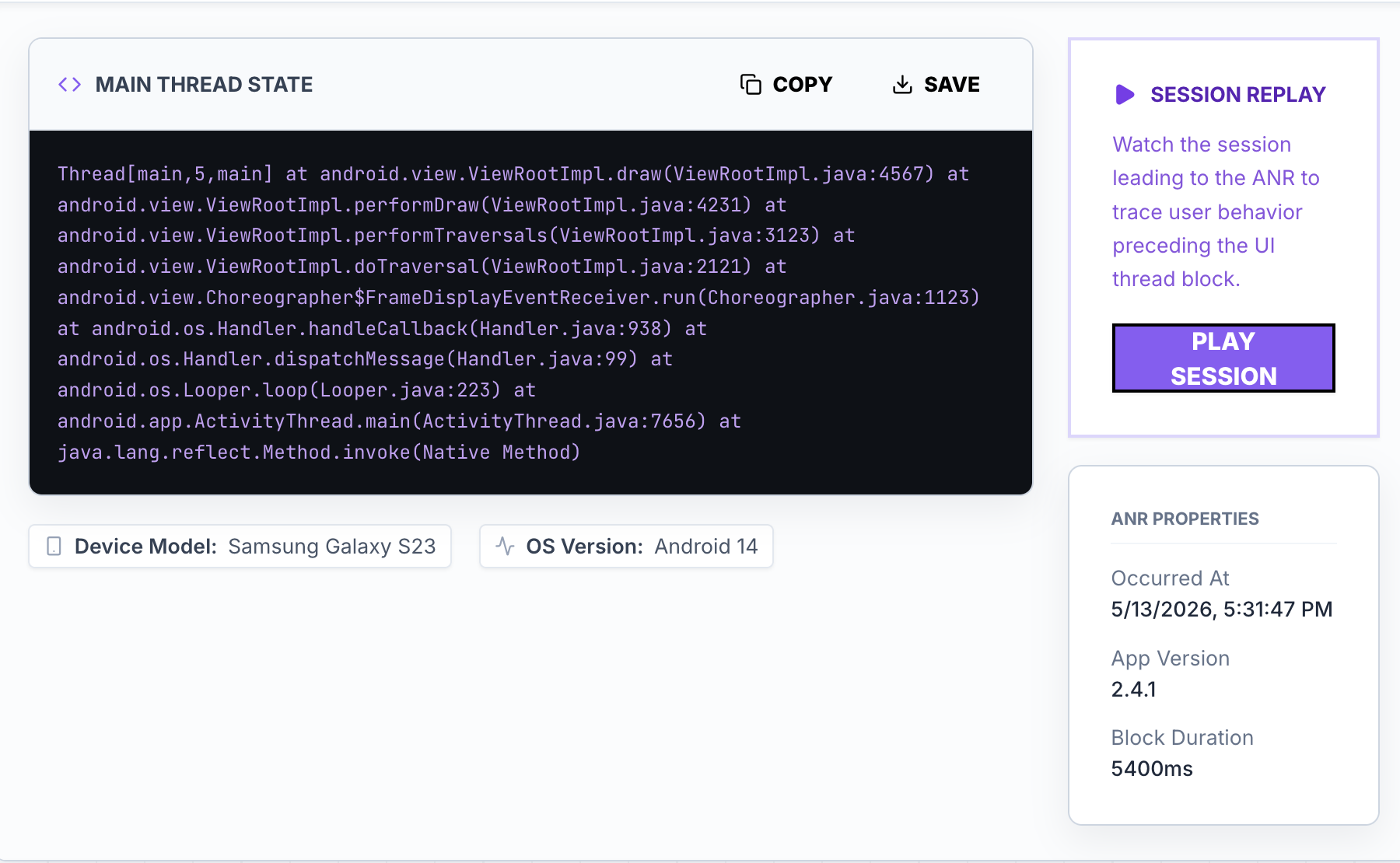
Production debugging should begin with the session that proves the bug
Debugging slows down when the evidence is split between a metric dashboard, a crash tool, a replay clip, a support ticket, and a chat thread. The team spends time reconstructing the story before it can fix anything.
Rejourney groups repeated signals and keeps replay, crash, API, event, device, release, and journey context together so the bug has a reproducible shape.
That context can then be handed to an engineer or AI coding workflow with enough detail to start testing a fix instead of asking users to reproduce the failure.
Start from the question the team needs to answer
Replay is most useful when it is tied to a specific product or support question: why a flow dropped, why a user got stuck, why a release created tickets, or why a screen behaved differently in production than it did in QA.
For developers, the implementation goal is to make that session searchable and explainable later. Capture the route or screen, release version, platform, product events, and the technical signals that explain what happened around the visual session.
- Route or screen name
- SDK and app version
- Key product events
- Failed requests, console logs, crashes, or ANRs
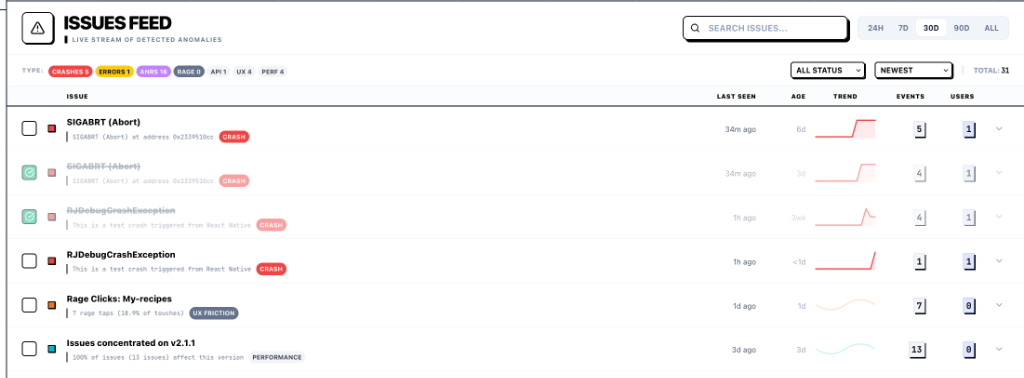
Use the replay to find the pattern behind the clip
A single recording can show the first clue, but it should not become the whole argument. After watching the session, filter for similar routes, devices, versions, failed requests, or journeys to see whether the behavior repeats.
The productive loop is to move between the individual session and the aggregate views. Replay explains the moment; journeys, heatmaps, events, and stability views show whether that moment deserves engineering time.
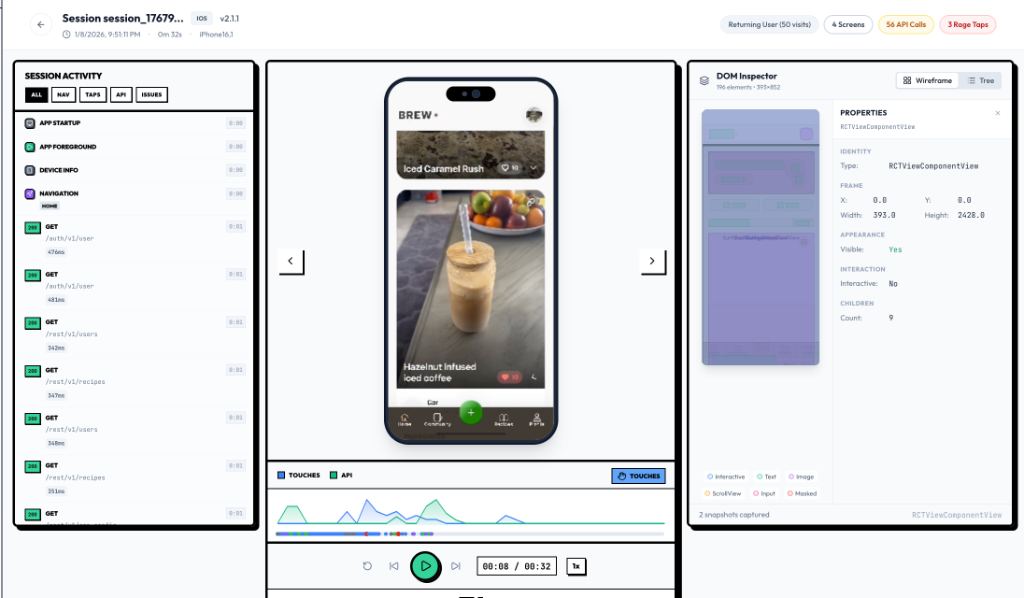
Keep capture boring, private, and reliable
Treat replay instrumentation like production telemetry. Mask sensitive fields by default, verify the SDK does not capture private content, and roll the integration out first on a flow where the team can quickly validate data quality.
Once the basics are trustworthy, expand coverage intentionally. Good replay data is consistent enough that a ticket, release review, or bug report can point to a session and everyone can inspect the same facts.
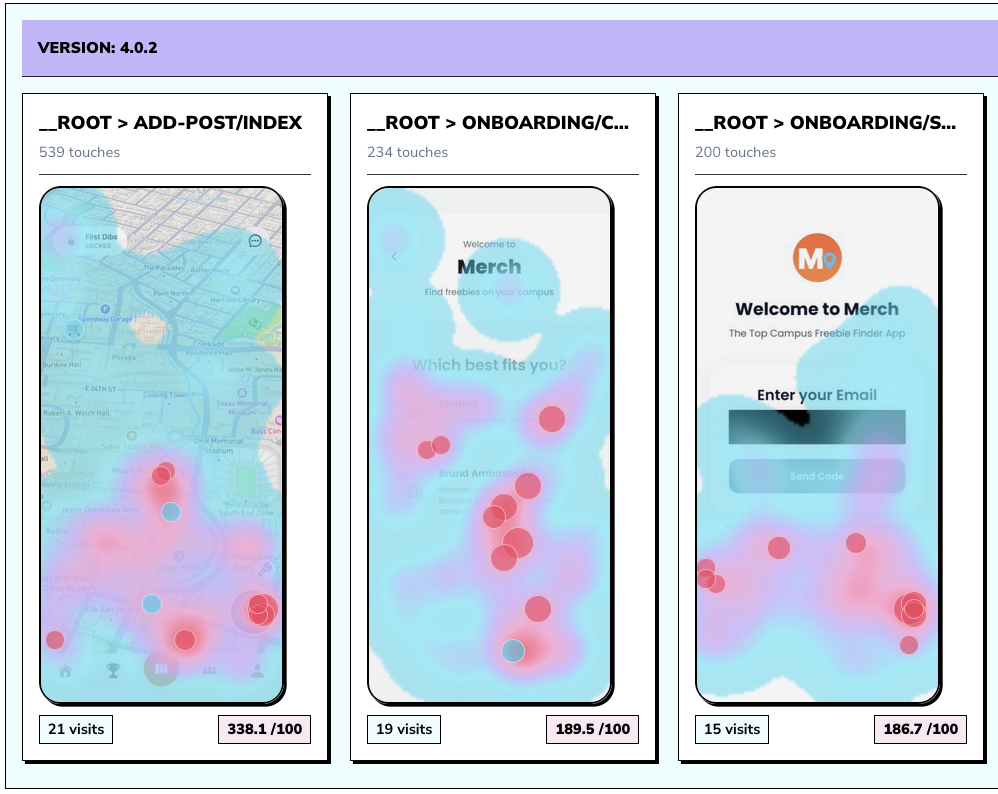
Implementation notes
These are the checks another engineer should be able to use before trusting the feature in production.
- Name routes, screens, and important states clearly enough that another engineer can search for them later.
- Attach release, app version, browser, OS, and device context before relying on replay for triage.
- Mask private UI by default, then explicitly allow only the surfaces the team needs.
- Verify one successful and one failed session for the target flow before calling the integration ready.
When to use a lighter signal
- The stack trace alone is enough to reproduce most production issues.
- Your product bugs do not depend on user path, UI state, device, release, or network context.
- Your existing observability tool already connects crash context to replay and product behavior.
Questions teams usually ask
What makes debugging autonomous?
The workflow becomes more autonomous when issue evidence is grouped, replay links are attached, context is structured, and the next agent or engineer can start from reproducible facts.
Does this replace crash reporting?
No. It complements crash reporting by adding replay, product path, events, device, release, and API context around the crash or failure.
Can this help with ANRs and freezes?
Yes. ANR and freeze triage is stronger when the session shows what the user was doing before the app stopped responding.
Related reading
- Pricing: See Rejourney's fixed-price plans and included platform limits.
- Live demo: Open the demo dashboard and inspect the replay, heatmap, journey, and stability views.
- React Native SDK: Install mobile session replay for React Native and Expo apps.
- Web SDK: Add browser session replay, analytics, and network capture to a web app.