
1. Shared identifiers
Shared identifiers
A session ID, route, screen, region, event, release, request, crash, and user segment are only useful if they mean the same thing across product, data, support, and engineering.
Standardized context
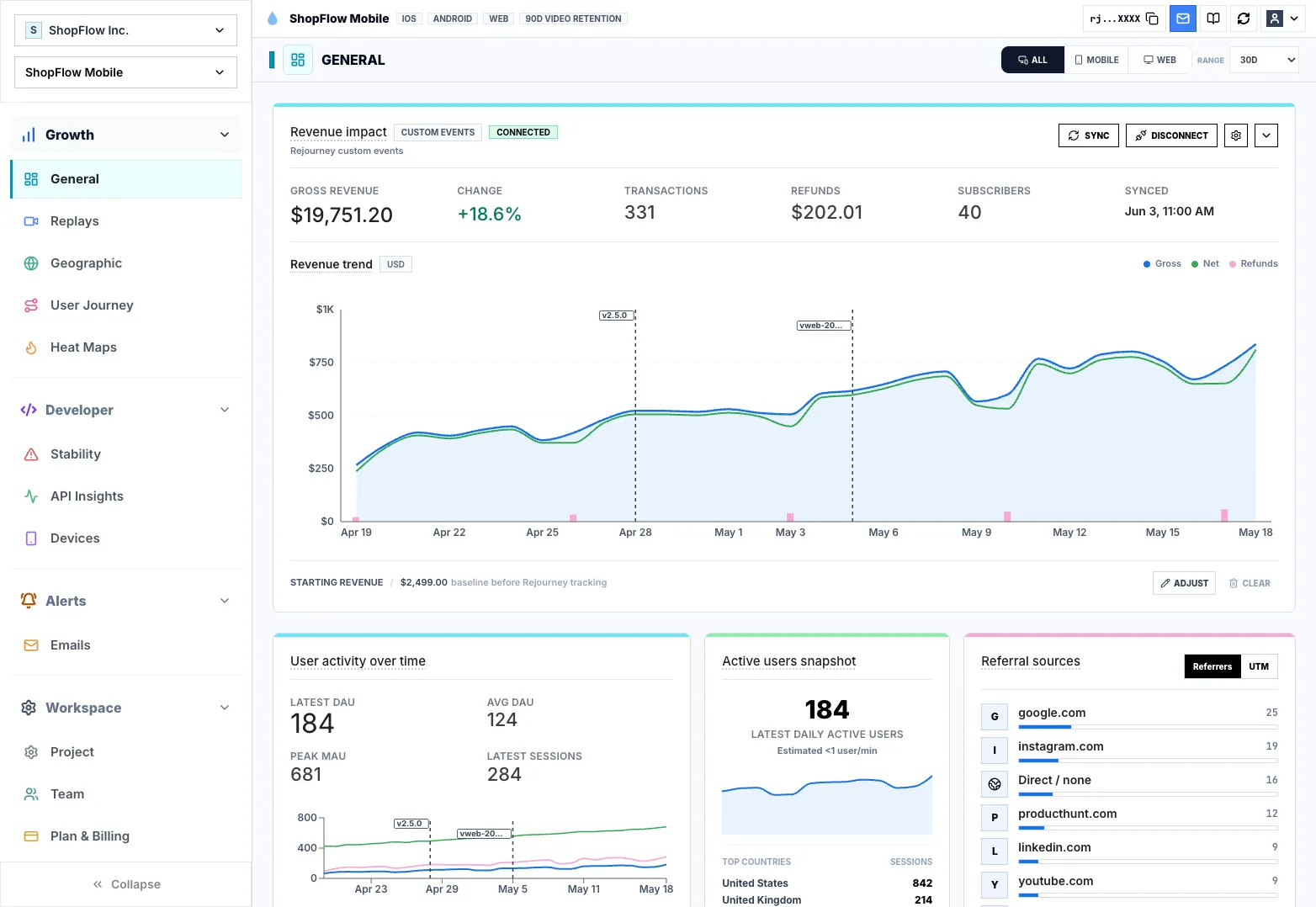
Turn sessions, regional signals, events, and technical evidence into consistent context that teams can query, share, compare, and hand off.
Install alongside your existing analytics and evaluate it with real sessions before committing.
Verified customer result
93% onboarding completion
Campus Merch
Session evidence helped the team isolate a Safari layout failure and restore a critical onboarding path.
From signal to answer
1. Shared identifiers
A session ID, route, screen, region, event, release, request, crash, and user segment are only useful if they mean the same thing across product, data, support, and engineering.
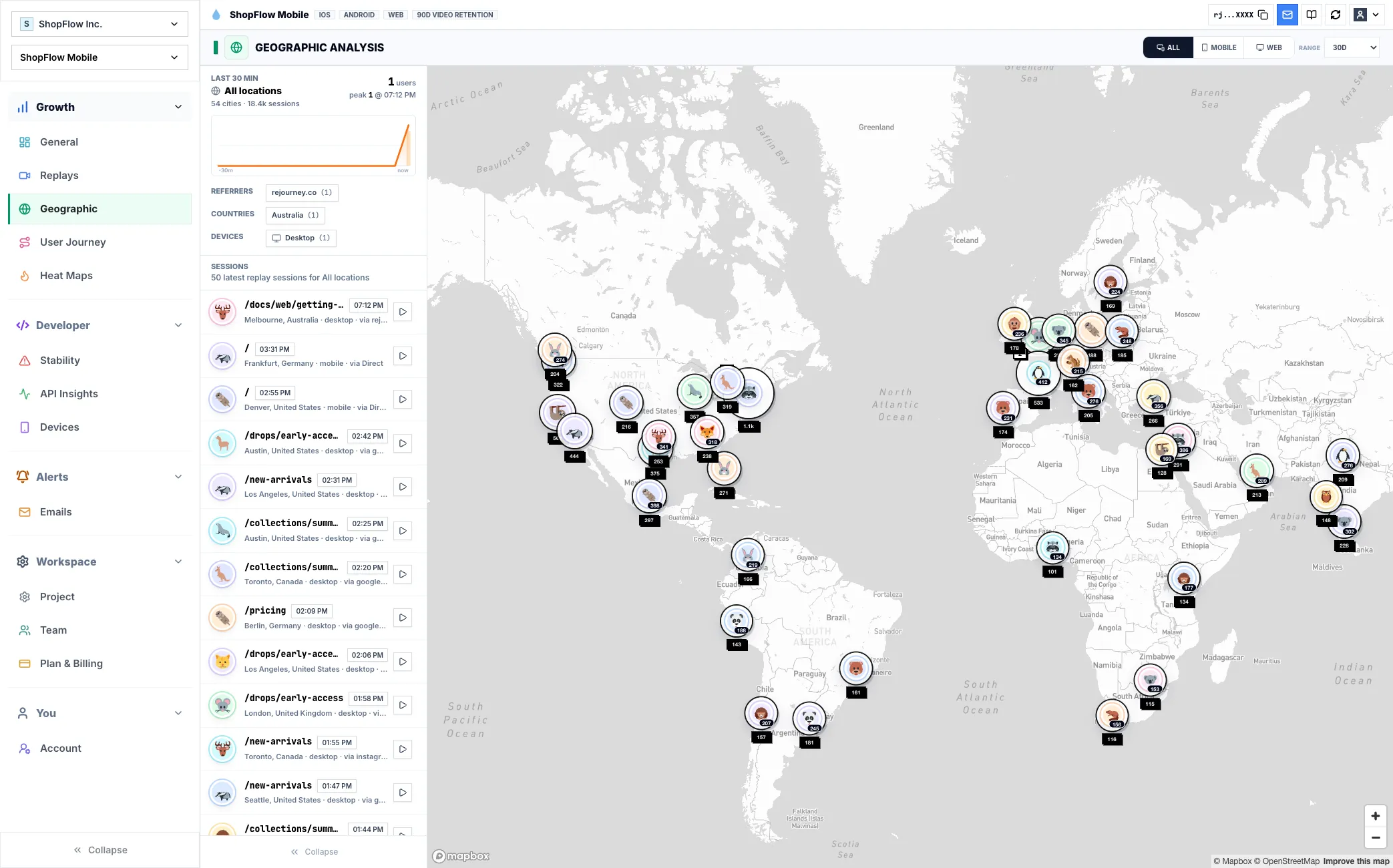
2. Replay-linked context
Rejourney standardizes those signals around the session so teams can compare issues, reopen evidence, and avoid rewriting the same debugging notes in every ticket.
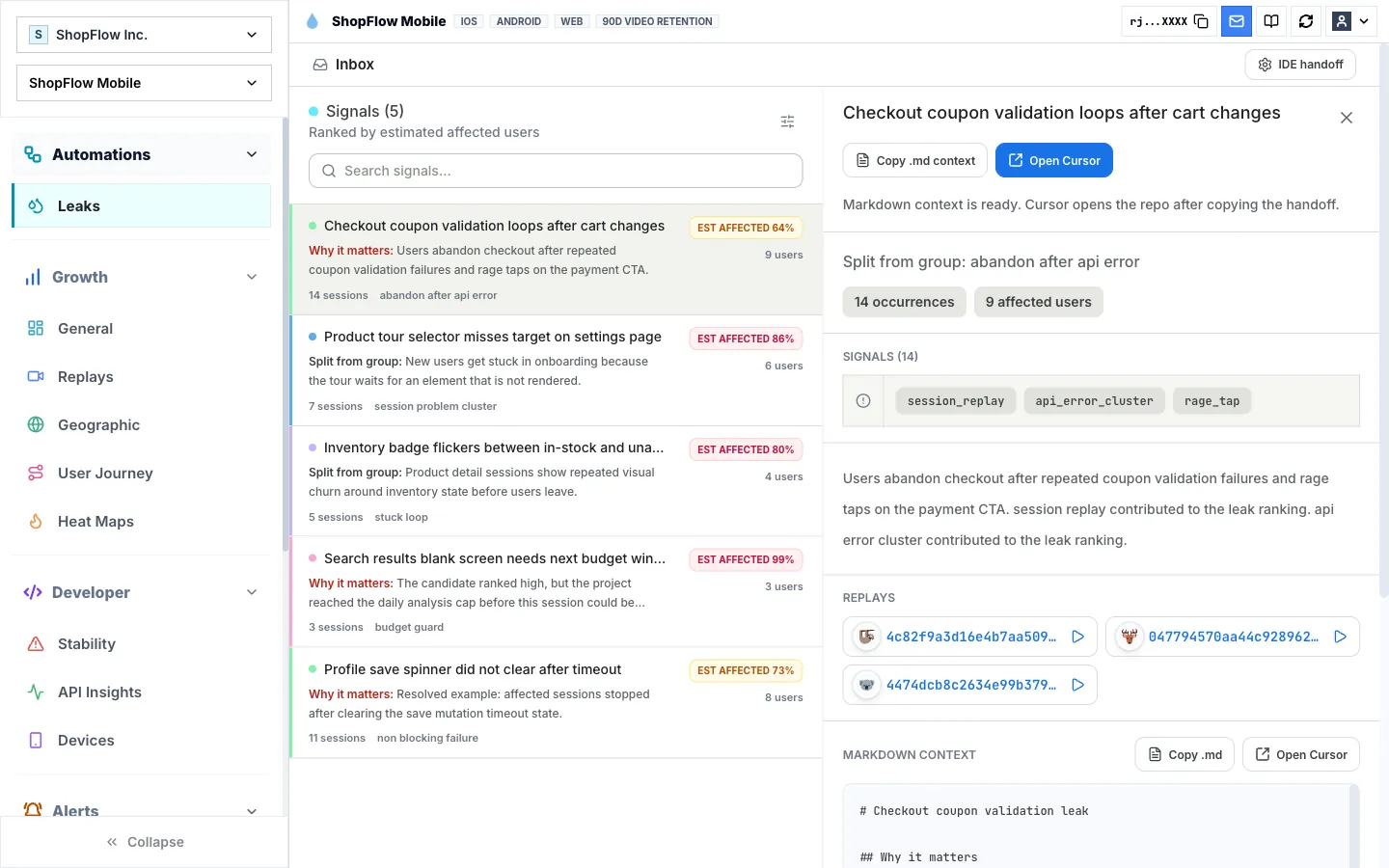
3. Exportable evidence
That gives data teams a cleaner layer for analysis while keeping the evidence attached to real user behavior.
Keep exploring
It is a consistent way to describe sessions, screens, events, regions, releases, requests, crashes, and issues so different teams can interpret the same evidence.
Replay is easier to trust when the session carries structured metadata that can be searched, compared, and reopened later.
Data teams use it for clean analysis, product teams use it for prioritization, and engineering teams use it for reproducible debugging.
Start with a real product
Start free with 5,000 monthly sessions, unlimited analytics events, and no credit card.